
Le socle : une base patients territoriale orientée analyse populationnelle
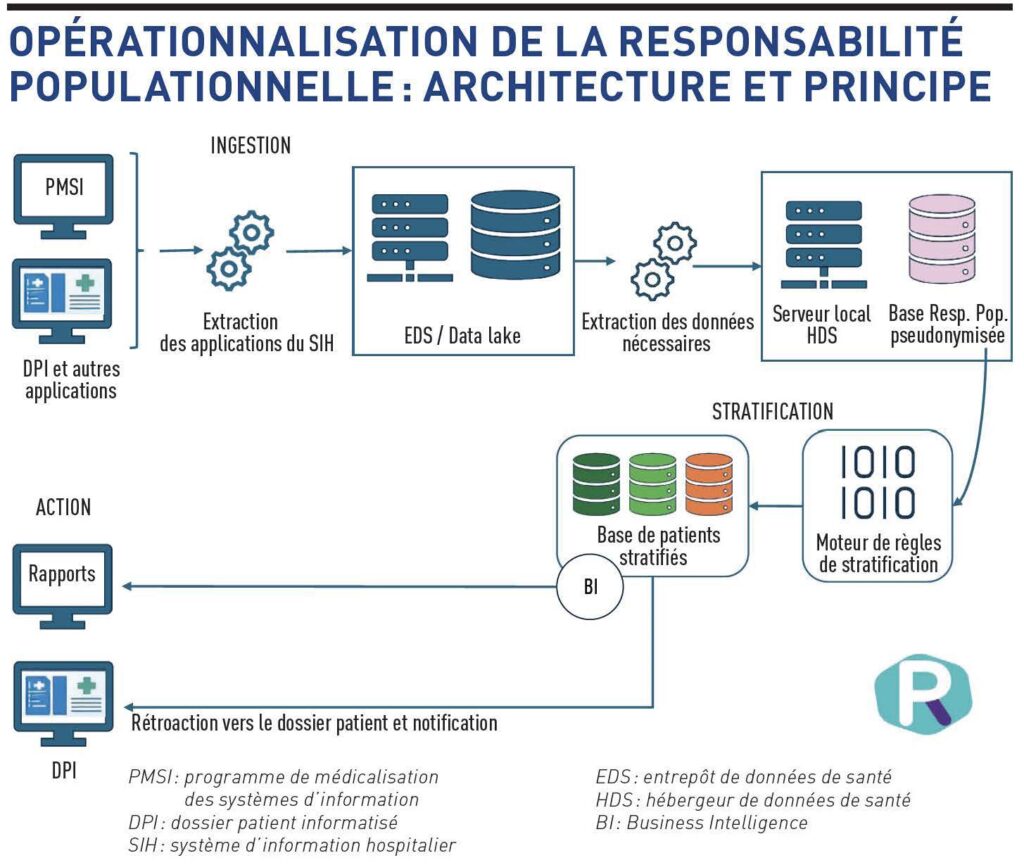
Au coeur de la responsabilité populationnelle se trouve une base de données patient, conçue pour permettre une analyse populationnelle structurée. Cette base regroupe les informations médicales connues des patients appartenant à la population cible, dans une logique de pilotage collectif et non de suivi individuel exhaustif.
Des données issues du PMSI, codées selon la CIM-10 et la CCAM
Dans sa forme la plus simple, cette base peut s’appuyer sur les données issues du programme de médicalisation des systèmes d’information (PMSI). Celui-ci présente un avantage décisif : il offre une structuration robuste des informations médicales, avec une identification fiable du patient et une codification homogène des diagnostics et des actes. Les diagnostics sont codés selon la classification internationale des maladies (CIM-10), les actes selon le codage des actes médicaux (CCAM), ce qui rend ces données immédiatement exploitables par des algorithmes d’analyse. Bien entendu, ce socle minimal gagne à être enrichi dès que possible par des données complémentaires issues du dossier patient informatisé, du biomédical ou, lorsque cela est disponible, de la médecine de ville.
Des éléments tels que la consommation de soins, la répétition d’actes ou la récence de certains événements viennent affiner la compréhension des trajectoires de santé. Cette montée en richesse du jeu de données ne remet toutefois pas en cause le modèle de base, qui doit rester centré sur des données structurées, comparables et exploitables à grande échelle. Il est essentiel de distinguer cette base populationnelle du dossier patient informatisé (DPI). La base de responsabilité populationnelle n’a pas vocation à contenir l’intégralité de la documentation d’un séjour, souvent non structurée d’ailleurs, et liée à un épisode de soins précis. Elle vise au contraire à agréger un ensemble ciblé de données structurées répondant aux besoins des algorithmes de stratification, après pseudonymisation afin de garantir la sécurité et la confidentialité des informations.
Une base alimentée par des flux d’ingestion de données
Sur le plan technique, cette base est alimentée par des flux d’ingestion de données. Dans un premier temps, ces flux sont généralement asynchrones, mais l’objectif est de tendre vers une ingestion plus proche du temps réel, afin que l’analyse populationnelle puisse être mobilisée directement par les professionnels depuis leur outil métier au moment de la prise en charge. Cette ingestion repose sur un concentrateur de données chargé d’assurer la convergence de la donnée issue du système d’information hospitalier, sa mise en qualité et sa structuration des informations. À l’hôpital, cette étape est indispensable : les données produites par les différentes applications du SIH sont rarement exploitables en l’état.
Les environnements d’entrepôts de données de santé, désormais présents dans les CHU, constituent un levier naturel pour préparer les données nécessaires à la responsabilité populationnelle. Le recours aux nomenclatures nationales conditionne la capacité à raisonner à l’échelle d’une population. En partant du PMSI, les établissements profitent d’une très bonne codification des actes faite selon la CIM-10 et la CCAM. La CIM-10 permet d’identifier les pathologies, tandis que la CCAM éclaire la nature et l’intensité des soins et donne des indices indirects sur la complexité ou la sévérité des situations. Sur ces données normalisées, un premier et véritable travail d’analyse populationnelle peut s’exercer. À terme, la base doit pouvoir être enrichie d’informations pour approfondir la vision patient, sans remettre en cause son modèle socle. C’est précisément cette convergence de la data qui constitue aujourd’hui le principal défi, plus que la technologie elle-même.
Le moteur de règles : transformer la donnée en décision
Une fois les données structurées, pseudonymisées et ingérées, le système de responsabilité populationnelle appelle un composant central : un moteur de règles. C’est lui qui permet de passer d’un ensemble de données patient à une vision populationnelle exploitable par les décideurs et les professionnels de santé.
Une stratification de la population
Le moteur de règles implémente les logigrammes définis par les communautés savantes et les acteurs du territoire. Il analyse automatiquement les données disponibles pour chaque patient, applique des règles métiers explicites et positionne chaque individu dans une strate de risque et un profil clinique populationnel. Le résultat de ce traitement est une stratification de la population, dans laquelle chaque patient appartient à un groupe homogène à un instant donné. Le moteur de règles va :
- analyser automatiquement les données de chaque patient ;
- appliquer des règles métiers définies par les experts cliniques et territoriaux ;
- positionner chaque patient dans :
– une strate de risque,
– un profil clinique populationnel.
Cette stratification constitue le coeur du raisonnement populationnel. Elle permet de visualiser la distribution des risques sur un territoire, de dimensionner des actions de prévention ou de suivi et de prioriser les ressources.
Un moteur de règle évolutif
Pour être pleinement opérationnel, le moteur de règles doit cependant rester évolutif. Les pratiques cliniques évoluent, les recommandations changent et les priorités de santé publique se transforment. Le moteur de règles doit donc être paramétrable sans redéveloppement lourd (ou sans réapprentissage, pour une version IA), permettre des versions successives, garantir la traçabilité des décisions prises et être enrichi par des algorithmes d’IA notamment pour outiller des outils de prédiction.
De l’analyse populationnelle à la rétroaction individuelle
Une fois la stratification réalisée, l’architecture technique donne une vue de la population classée selon ses risques, ce qui permet d’éditer tous les tableaux de bord nécessaires à la prévention et au pilotage de la santé. La responsabilité populationnelle ne se limite pas à produire des tableaux de bord statistiques, l’enjeu est de pouvoir passer de l’analyse globale à l’action concrète auprès des patients et des professionnels.
Faire converger les données au‑delà des silos applicatifs
Le système doit donc permettre la ré-identification locale, dans un cadre strictement sécurisé, pour enchaîner automatiquement une rétroaction vers le patient : ré-identifier le patient à l’intérieur de l’établissement/GHT, notifier les professionnels concernés par le patient lors de sa prise en charge, déclencher des rendez-vous, examens, suivis, notifier le patient (via MSSanté ou Mon espace santé) et enfin suivre l’exécution effective de ce qui est prévu, une condition indispensable pour piloter réellement les programmes de responsabilité populationnelle. C’est à ce stade que l’intégration entre les DPI, les logiciels métiers de ville et les services socles nationaux (Mon espace santé) devient critique pour le pilotage de la responsabilité populationnelle sur le territoire. La responsabilité populationnelle impose de faire converger les données au-delà des silos applicatifs, selon un schéma d’urbanisation cohérent, qu’il soit régional ou national, vers une structure de pilotage pertinente.
Emplacement de la structure de pilotage : un choix pragmatique
La question de l’emplacement de cette structure de pilotage est avant tout pragmatique : elle doit se situer là où les données sont les plus complètes et les plus exploitables. Aujourd’hui, ce rôle est souvent assumé au niveau de l’établissement ou du groupement hospitalier de territoire, qui dispose déjà des données et des capacités d’extraction nécessaires. À l’échelle régionale, certaines implémentations, comme celles portées par e-parcours 1, réalisent la stratification directement dans l’outil, sur la base des données disponibles, et produisent des indicateurs via des modules de business intelligence. À plus long terme, un pilotage national adossé à Mon espace santé représenterait un scénario idéal, mais il suppose des évolutions juridiques et, surtout, un niveau de codification en ville comparable à celui atteint aujourd’hui à l’hôpital.
La responsabilité populationnelle n’est pas freinée par un manque de technologies. Les briques nécessaires existent déjà : données structurées, entrepôts, moteurs de règles, services socles nationaux. Le véritable enjeu réside dans leur articulation, leur gouvernance et leur mise au service d’un objectif commun de santé collective. Urbaniser le système d’information pour la responsabilité populationnelle, c’est accepter de sortir d’une logique purement documentaire et hospitalo-centrée pour entrer dans une approche orientée données, territoires et parcours. C’est aussi reconnaître que la valeur ne se situe pas uniquement dans l’outil, mais dans la capacité à transformer l’information en décisions, puis en actions coordonnées sur le terrain. À ce titre, la responsabilité populationnelle agit comme un révélateur : elle ne demande pas un SI plus complexe mais, au contraire, un SI rationalisé, convergent sur la data, pour répondre aux besoins réels de la population et des professionnels qui en ont la charge.